··
devops11 min
Del polling teórico a cuatro paneles TRMNL en mi mesa
Después de comparar polling y webhook, monté el TRMNL en serio con cuatro pantallas e-ink que rotan junto al monitor, alimentadas por un FastAPI sobre Dokploy. Qué muestra cada panel, qué decisiones técnicas escondidas tiene y un par de cosas que no funcionaron a la primera.

posts/trmnl-paneles-dokploy-vps-eink.md
Escuchar este artículoNarración generada por IA
Hace unos días comparé los dos caminos posibles para llevar el estado de mi VPS a una pantalla TRMNL, polling con un endpoint JSON o webhook desde los timers que ya tengo. Me quedé con polling, sobre todo porque el control de qué aparece en la pantalla vive en mi servidor y no en el dispositivo, y porque pegaba más con la idea de "postal silenciosa" que con la de notificación inmediata.
Esta semana lo monté de verdad. Cuatro pantallas rotando cada quince minutos al lado del monitor, alimentadas por un servicio FastAPI en el mismo VPS de Dokploy. Este post es lo que dejé en pie, qué pinta cada panel, qué decisiones costaron más de lo que parecía y un par de cosas que no funcionaron a la primera.
El esqueleto, sin sobreingeniería
El backend es un FastAPI pequeño con cuatro endpoints, uno por pantalla. Cada uno devuelve un JSON plano que el TRMNL pinta con una plantilla Liquid pegada en su UI de Private Plugins. La pantalla pregunta cada N minutos, recibe el JSON, renderiza el Liquid y deja el resultado en e-ink. No hay estado en el dispositivo. Si quiero cambiar qué aparece, toco el endpoint y la siguiente vuelta lo aplica.
El servicio vive como un proyecto más en Dokploy, detrás de Traefik con dominio propio, certificado de Let's Encrypt y un middleware de rate limit a 60 req/min por IP. Las peticiones del TRMNL llevan un bearer de 256 bits que se compara con hmac.compare_digest y el origen solo acepta TLS firmado por Cloudflare, vía Authenticated Origin Pull. Si alguien intenta hablar directo con el VPS sin pasar por CF, el handshake falla antes de tocar el backend.
El código de cada pantalla queda casi declarativo. El endpoint compone un screen a partir de uno o varios collectors (host, traefik, dokploy, umami, docker, crowdsec), y los collectors son la única pieza con lógica real. La idea es poder añadir una pantalla nueva sin tocar nada que ya funcione.
Overview, lo que se mira primero
La pantalla por defecto es la de resumen general. Cuatro cifras grandes arriba (CPU, RAM, disco, uptime) y una lista de servicios con su latencia y el estado del último deploy.

La parte de host la saco con psutil dentro de un hilo aparte, porque cpu_percent(interval=1) bloquea un segundo entero muestreando, y no quiero que el event loop de FastAPI se quede parado en cada refresco. La parte de servicios sale de un colector llamado service probes que hace un HEAD a cada URL configurada y mide la latencia. La lista de servicios viene de una env var con JSON inline, así que añadir uno nuevo es editar la variable en Dokploy y redeploy. No requiere rebuild.
La columna de "último deploy" es la única que necesita autenticarse contra la API de Dokploy con un token. Cuento como OK los deploys terminados sin error, como deploy los que están corriendo y como fallo los que petaron. Si la API de Dokploy no responde, la columna queda en blanco y el resto del panel sigue funcionando. Es una decisión consciente, ningún colector debería tumbar la pantalla entera.
Resources, cuando me interesa el detalle
Overview cabe en un golpe de vista, pero a veces quiero saber qué contenedor está chupando CPU. Para eso está Resources, con barras de CPU, RAM y disco, swap, red y un top de contenedores ordenados por consumo.

El detalle de los contenedores tira de la API HTTP del Engine de Docker, no directamente del socket. Entre el backend y Docker hay un wollomatic/socket-proxy con una allowlist regex limitada a /containers/json y /containers/{id}/stats. El endpoint /containers/{id}/json queda bloqueado con 403 a propósito, porque ese sí expone variables de entorno de otros contenedores y no me hace falta para nada en este panel. Defensa en profundidad por si el backend se viera comprometido, no le doy más superficie de la imprescindible.
Las primeras versiones de Resources mostraban el nombre completo de cada tarea de Swarm (algo del estilo blog-qfnocv.1.o3ywn067fsw6e5ltw776et19t), que cabía mal en la tabla y no decía nada útil. Ahora el colector resuelve el nombre del service de Compose por la label com.docker.compose.service y solo cae al id largo cuando no existe. Si el mismo nombre aparece en dos proyectos distintos (es lo que pasa con postgrest), se desambigua con el prefijo del proyecto, infrastructure/postgrest y mybox/postgrest. También oculto la columna mem_limit_mb cuando coincide con la RAM total del host, porque eso significa que el contenedor no tiene límite y el dato solo añade ruido.
Una cosa que me costó descubrir, la imagen del socket-proxy es distroless, no trae wget ni curl dentro, así que no puedo ponerle un healthcheck que valide su API. De vez en cuando se cuelga sin avisar y la pantalla aparece con la tabla de contenedores vacía. La salida es bestia, un restart manual del contenedor por SSH, pero está documentado y por ahora no he tenido más de un episodio cada par de semanas. Si se vuelve recurrente lo cambiaré por una variante con shell mínimo, aunque pierda parte del hardening.
Traffic, leyendo el access.log de Traefik a pelo
Traffic es la pantalla que más decisiones técnicas escondidas tiene. Muestra rpm, errores 5xx en los últimos quince minutos, p95 y p99 de latencia, bans activos del firewall y dos columnas con top de dominios y últimos deploys.

La fuente para todo lo de tráfico es el access.log de Traefik en formato JSON. Lo primero que pensé fue meter Loki o Prometheus, pero el blog no factura nada que justifique mover una pieza más. Lo segundo fue parsear el log entero en cada petición, lo cual escala mal pero funciona en un VPS pequeño. Lo tercero, que es lo que dejé puesto, es leer solo los últimos dos megas del fichero (un seek al final, leer hacia atrás), descartar la primera línea por si quedó truncada y filtrar por ventana temporal de quince minutos. En un VPS con pocos rpm de media eso son menos de 30000 entradas, las parseo a JSON o CLF, calculo p50, p95 y p99 con statistics de la stdlib, agrupo por host y termino.
Una rareza simpática que aparece en el top de dominios desde que monté el TRMNL es el propio backend de los paneles. Como cada pantalla tira una request cada quince minutos y son cuatro pantallas, mantiene un caudal pequeño pero constante. Verme a mí mismo en la pantalla recordándome que la pantalla funciona tiene su gracia.
La columna de "bans activos" viene de CrowdSec, llamando a su Local API con la clave de bouncer. Aquí también me hice un nudo, los eventos de baneo en las últimas 24 horas y los bans activos ahora mismo son cosas distintas. Lo que quería ver en la pantalla era el segundo, "ahora mismo hay 47 IPs cerradas", no "hoy se baneó a alguien". Tuve que cambiar la consulta de /v1/alerts a /v1/decisions?type=ban y filtrar las que no hayan caducado. El detalle parece tonto pero te puede llevar media hora si vas a pelo. Aparte del global, abajo a la derecha aparece un contador de SSH bans específico, porque conviene saber si el ruido viene de la capa web o de gente intentando login al puerto.
Blog, Umami por la base de datos en vez de por API
La cuarta pantalla es la del propio blog, con páginas vistas y visitantes únicos en 24 horas, comparativa contra la semana anterior y las dos columnas más útiles, top de páginas y top de referrers.
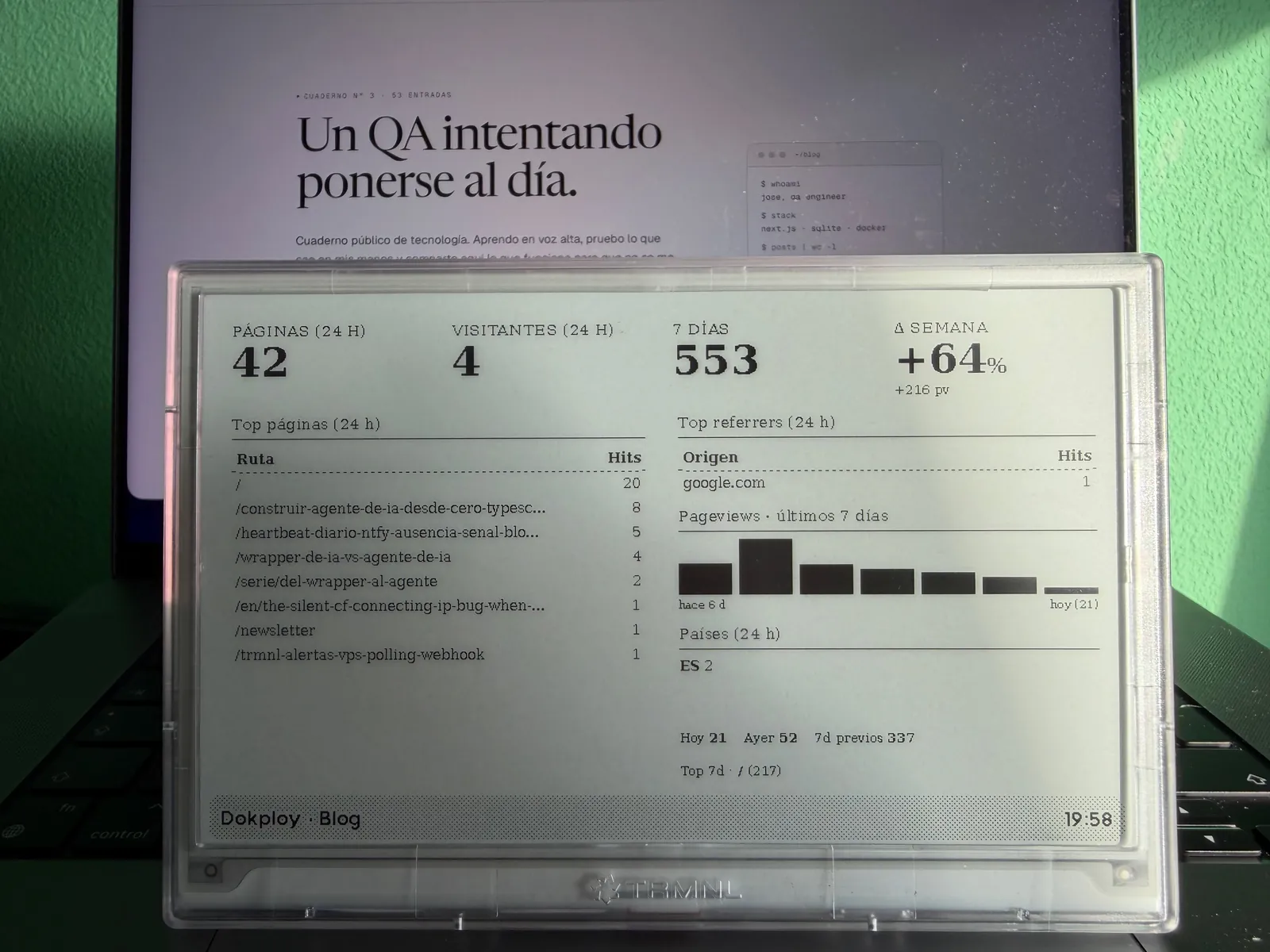
Para los datos de tráfico web tiro de Umami, que ya tengo self-hosted. La API oficial exige hacer POST /api/auth/login con usuario y contraseña de admin, recibir un token y rotarlo. Para un panel read-only que vive dentro de la misma red Docker me parecía caro, así que abrí el camino corto, conectar directamente a la base de datos Postgres de Umami con un rol umami_ro que solo tiene SELECT en tres tablas (website_event, website y session). Sin admin password, sin tokens que rotar, sin sesiones.
El coste es que me acoplo al schema interno de Umami, que es un proyecto vivo y cualquier migración mayor puede renombrar columnas. Asumido y documentado, en el peor caso pierdo la pantalla un rato hasta que actualizo la query. A cambio, las cuatro métricas principales, los dos tops y la tabla de países salen en una o dos consultas y se cachean 60 segundos para no martillear la BD.
Una semana después de tener la pantalla en marcha le añadí un sparkline diario de los siete días previos al lado de las tablas. La forma visual te dice más rápido que el porcentaje si el tráfico viene en subida, si lleva la inercia de un pico aislado o si lleva tres días planos. La query de Umami solo cuenta lo que ha ocurrido entre dos timestamps, no recuerda el ayer, así que monté una persistencia en el backend, un JSON pequeño en un volumen /data que guarda el snapshot diario a una hora fija. La sparkline lee de ese fichero y el delta semanal pasa a ser absoluto además de porcentual (+216 pv da bastante más contexto que un +64% a secas).
La pantalla muestra también, abajo a la derecha, el desglose de hoy, ayer y los siete días previos, junto con la página más leída de los últimos siete días. Sirve para contextualizar el delta, "+64% sobre 337" no es lo mismo que "+64% sobre 4". El bloque de países usa códigos ISO de dos letras directamente, sin traducir, porque la pantalla es estrecha y "ES 2" cabe donde "España" no. Son decisiones de UI que solo se entienden cuando llevas una semana mirando el panel y echas en falta el dato.
Seguridad, por las dudas
El backend no expone /docs, /redoc ni /openapi.json, tampoco hace falta. El bearer de 256 bits se compara con hmac.compare_digest, no con == (tiempo constante, sin canal lateral). El proceso corre como USER 1001, con cap_drop ALL, no-new-privileges, read_only y un tmpfs mínimo en /tmp. Las imágenes están pinneadas por digest, el uv.lock está commiteado y UV_NO_BUILD=1 impide compilar wheels arbitrarios desde sdist durante el build. Los bumps de dependencias pasan por un script con cuarentena de 48 horas, equivalente al minimum-release-age que uso en pnpm para el blog.
Hay un riesgo aceptado que vale la pena nombrar, el contenedor se une a la dokploy-network, la misma red interna que comparten la BD de Dokploy, Infisical y todas las apps de mis proyectos. Si el backend del TRMNL sufriera un RCE, el atacante tendría visibilidad de red a esos servicios. Está mitigado por todas las barreras anteriores y por la capa de Cloudflare delante con rate limit por cf-connecting-ip y CrowdSec bouncer, pero conviene saber que es un riesgo inherente al diseño de Dokploy con la red compartida. No es una mancha que puedas frotar, es una decisión.
Lo que no entró en la primera versión
Quise meter una pantalla específica para alertas de seguridad (eventos de AIDE, intentos de SSH, picos de 4xx por IP) pero al maquetarla me di cuenta de que estaba duplicando el rol del bot de Telegram y los push de ntfy con heartbeat diario. Si una intrusión está ocurriendo, no quiero esperar quince minutos a que la pantalla se refresque, quiero la notificación al teléfono con prioridad cinco. El TRMNL se queda con su rol de "postal silenciosa", no de canal de incidentes.
También barajé un panel financiero (la cuenta del broker, posiciones, alertas de tipos) y un panel doméstico (clima, próximos eventos del calendario). Los tengo en mente para la siguiente vuelta. La gracia de los Private Plugins de TRMNL es que cada uno es independiente, puedo añadir endpoints sin tocar los que ya están en marcha.
El día siguiente al deploy
Llevo cuatro días con el dispositivo encendido junto al monitor. Lo miro un par de veces por sesión, casi sin darme cuenta. Cuando todo está verde, deslizo la vista y sigo trabajando. El día que vi un 5xx en Traffic me acerqué al log y resultó ser un bot intentando rutas que no existen. Cero acción real, pero la pantalla cumplió su parte, me empujó a mirar.
El patrón de "yo voy a buscar la información" se ha convertido en "la información está donde puedo verla sin esfuerzo". Que era exactamente lo que escribí en el post anterior antes de pulsar el botón de comprar. Esta vez la decisión y la implementación quedaron alineadas, lo que no siempre pasa.

Jose, autor del blog
QA Engineer. Escribo en voz alta sobre automatización, IA y arquitectura de software. Si algo te ha servido, escríbeme y cuéntamelo.
Deja el primer comentario
¿Qué te ha parecido? ¿Qué añadirías? Cada comentario afina la siguiente entrada.
Si esto te ha gustado

devops8 min
Un TRMNL para las alertas del VPS, polling o webhook
Estoy valorando llevar las alertas de mi infraestructura a una pantalla de e-ink TRMNL. Comparo los dos caminos posibles, polling con un endpoint JSON detrás de Cloudflare Access y webhook desde los timers que ya tengo.

herramientas5 min
OpenClaw para testing y QA: automatiza lo que antes hacías a mano
OpenClaw no solo sirve para verificar integridad: regresión visual, monitorización de endpoints, análisis de logs, smoke tests post-deploy y auditoría de seguridad continua. Casos de uso reales para testing y QA.

devops13 min
Cómo montamos la infraestructura con Dokploy (y por qué dejamos Vercel)
Un VPS, Docker, Traefik y Dokploy. Así alojamos el blog y diez proyectos más. Por qué dejamos Vercel, por qué elegimos Dokploy sobre Coolify y qué ganamos y perdimos en el camino.